Case Study · LensHH-LT
One kernel, laptop to H100 — merit-function throughput across hardware
LensHH-LT evaluates the same merit function — bit for bit — on a fanless laptop, a MacBook Air, gaming desktops, and rented A100 / H100 GPUs. The GPU value pre-screen treats every candidate lens as one thread, reaching hundreds of thousands of merit evaluations per second; the CPU runs the analytic-Jacobian polish. Across eight machines and three merit functions, the GPU result matches the CPU to the floating-point noise floor.
The benchmark
MeritEvalBench times the primitives the optimizer is built
from, with no LM loop in the way. It measures whole-merit
value throughput — how many candidate designs
per second the engine can score — on the CPU (all cores) and on
the GPU, and it separately times the analytic Jacobian
(residuals plus the full derivative matrix in one pass) on the CPU.
The GPU and CPU paths call the same compiled
evaluate_merit, so the GPU result is bit-identical to the
CPU by construction. The GPU is used as a value-only
pre-screen — a wide Multistart sieve — while the
Levenberg–Marquardt polish, with analytic derivatives, runs on the
CPU.
Eight systems
The identical Linux / Windows / macOS binary, exercised from a low-power
laptop up to a datacenter H100. GPU support ships as a prebuilt native
cubin (sm_80 / 89 / 90 / 120), so there is no CUDA toolkit
to install on the target and no multi-minute first-run compile —
the RTX 5070 Ti below ran with no SDK installed at all.
| System | CPU | GPU | GPU architecture (SMs) | Memory bandwidth |
|---|---|---|---|---|
| Laptop | Core i7-1255U (12T) | — (Iris Xe) | — | — |
| MacBook Air | Apple Silicon (ARM64) | — (integrated) | — | — |
| Mini-desktop | Ryzen 3 5300G (8T) | — (Radeon) | — | — |
| Desktop | Core i5-13400F (16T) | RTX 4060 | Ada sm_89 (24) | 272 GB/s |
| Workstation | Ryzen 7 9800X3D (16T) | RTX 5070 Ti | Blackwell sm_120 (70) | ~896 GB/s |
| Cloud | 16 vCPU | A100 40GB | Ampere sm_80 (108) | ~1.55 TB/s |
| Cloud | 24 vCPU | H100 80GB | Hopper sm_90 (132) | ~3.35 TB/s |
| Cloud | 28 vCPU | RTX PRO 6000 | Blackwell sm_120 (188) | ~1.79 TB/s |
Three merit functions
The three test designs span a wide range of merit-function size — and the GPU advantage grows with that size, because the device hides memory latency behind more parallel work.
- Cooke triplet — 8 surfaces, 12 variables; a light merit (7 operands → 240 expanded).
- Imaging lens · WAVEX — a patented multi-element imaging lens, 21 surfaces, 36 variables, with a
WAVEXwavefront-error operand sampled on Forbes quadrature (6 rings × 12 arms): 8 operands → 241 expanded. - Imaging lens · WAVEX + SENS — the same lens with an added
SENSsensitivity operand to drive a more manufacturable design.SENSperturbs every surface, expanding the merit to 8 operands → 4,686 sub-operands — roughly 19× more work per evaluation.
All three: three wavelengths, three fields, infinite conjugate. The imaging lens is Example 2 of U.S. Patent US 12,321,041 B2 (Tanabe et al.).
Merit evaluations per second
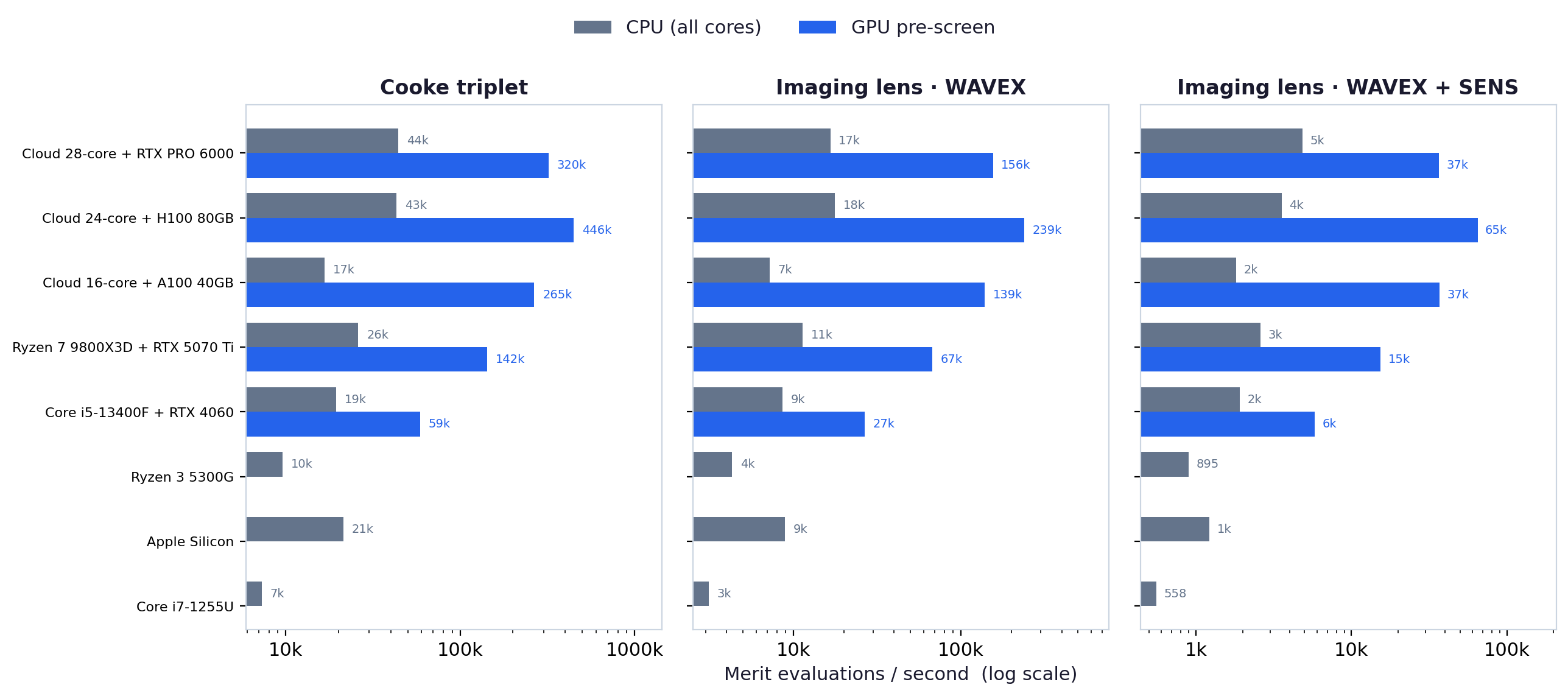
On the GPU, every candidate lens is a thread: the device scores tens of thousands of designs in one launch. An H100 reaches roughly 446k merit evaluations per second on the Cooke triplet and 65k/second on the heaviest (WAVEX + SENS) merit; even a consumer RTX 5070 Ti clears 142k and 15k. The printed CPU multiples depend on how many cores the host has, so the figures above lead with absolute throughput — the number that actually scales with the hardware.
Bandwidth-bound, not FP64-bound
The whole-merit kernel is bound by memory bandwidth, not double-precision compute. The clearest evidence: the consumer-class Blackwell card matches the A100 within about 1% on the heaviest merit (37k vs 37k evaluations/second) despite having roughly 14× less FP64 throughput. Across all four GPUs the ranking tracks memory bandwidth — from the 4060's 272 GB/s up to the H100's HBM3 — not the FP64 spec. In practice that means a well-chosen consumer GPU delivers datacenter-class merit throughput for this workload.
Analytic derivatives on the CPU
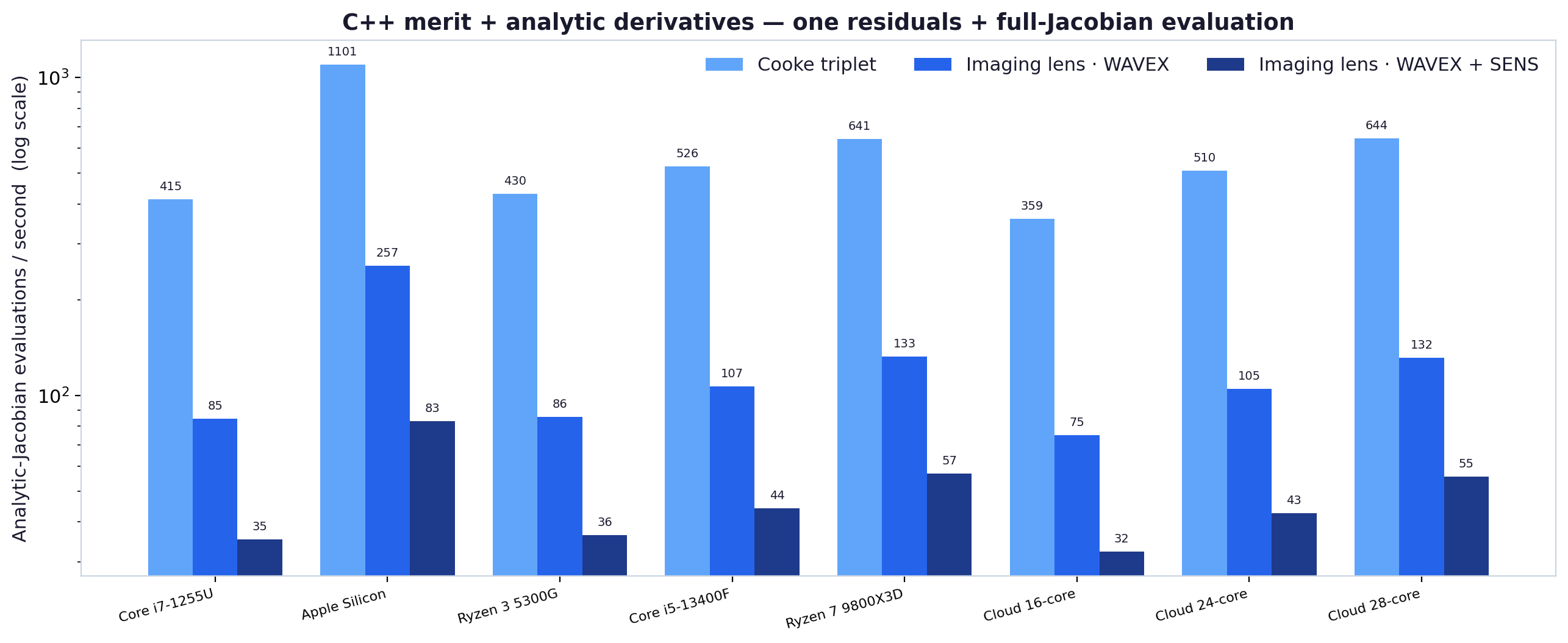
The Levenberg–Marquardt polish needs the Jacobian, and LensHH-LT computes it analytically — residuals and the full derivative matrix in a single forward-mode dual-number pass, far faster than finite differences. This is the CPU's job in the hybrid pipeline: the GPU sieves a wide field of candidates by value, then the CPU refines the survivors with exact derivatives. The chart shows that single-eval cost scales with the host CPU across every machine in the sweep.
What's worth taking away
- One engine, everywhere — bit-identical. The same kernel runs on a laptop, a MacBook Air, a desktop, and a datacenter GPU, and the CPU and GPU agree to the floating-point noise floor.
- The GPU is a wide value pre-screen. Every lens is a thread; a single launch scores thousands of candidates, then the CPU polishes the survivors with analytic derivatives.
- Memory bandwidth is the lever, not FP64. A consumer Blackwell card matches an A100 on this workload — so the price/performance sweet spot can be a consumer GPU.
-
No CUDA toolkit on the target. Prebuilt native cubin
(
sm_80/89/90/120) means instant launch on every card, including the latest Blackwell GPUs — nothing to install, no first-run compile.
Try it on your hardware
LensHH-LT runs on Windows, Linux, and macOS, and the GPU pre-screen engages automatically when a CUDA device is present. Download the free trial and run a Multistart on your own designs.
Download free trial Back to LensHH-LT